Claude Codeの全社展開で詰まるのは技術ではなく情報漏えいの不安。社内ルール設計の要点を実務の手順で具体化します。
 無料相談受付中
無料相談受付中いきなり作らない。
AIで何がどう変わるかを、先に見極める。
- ノーコードの卒業先、AIネイティブ受託。事業の文脈で要件から実装まで伴走
- 45分・Web。検討段階のご相談・資料だけでも歓迎。しつこい追客はしません
目次
Claude Codeを安全に業務利用する社内ルール設計 情報漏えいを防ぐ運用の作り方
Claude Codeの全社展開で本当に詰まるのは技術ではなく「情報漏えいの不安」です。社内ルールを5項目で固め、運用と技術の二段で守る設計を、実務の手順で具体化します。
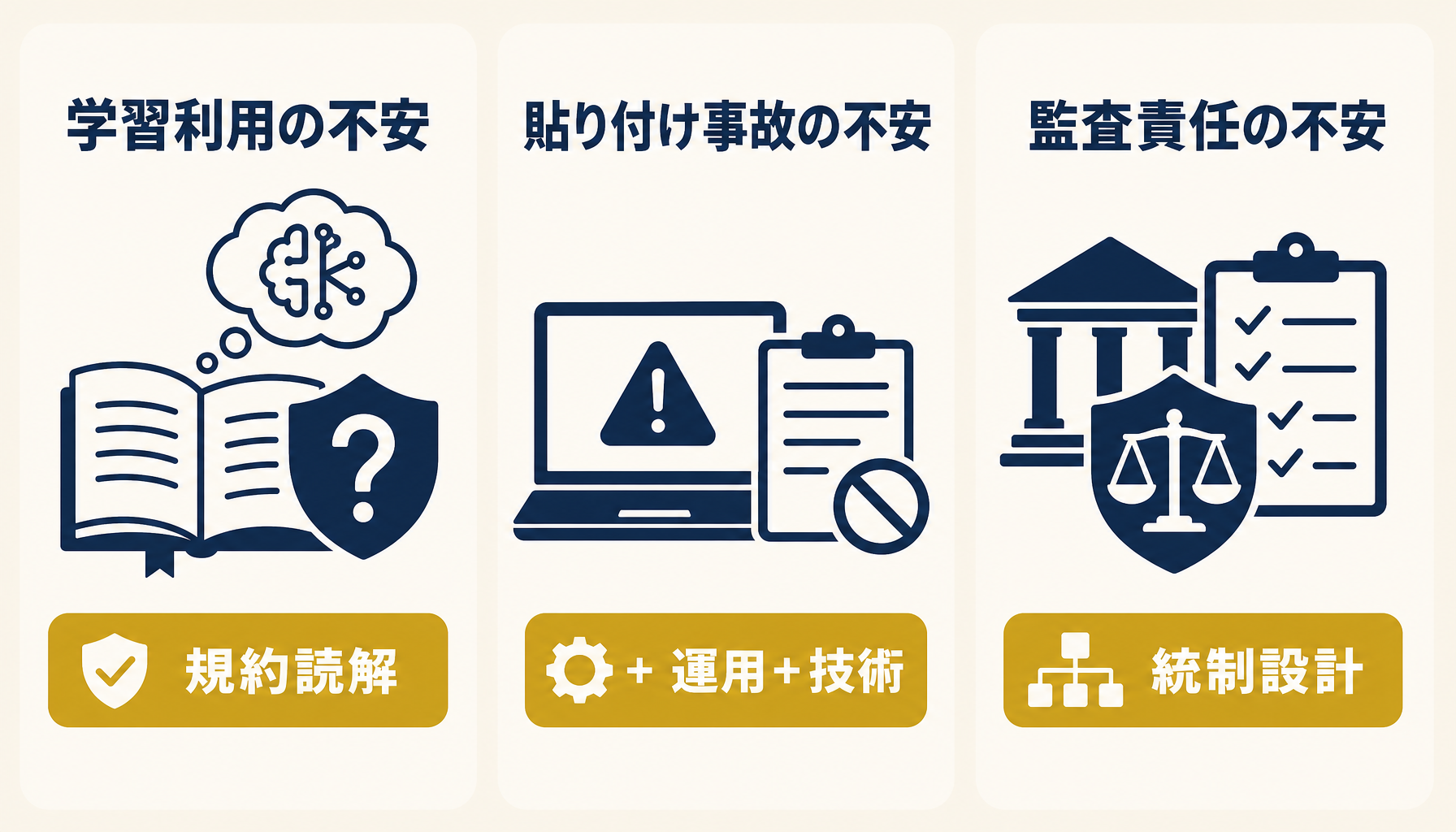 図1: 全社展開でつまずきやすい3つの不安(学習利用・貼り付け事故・監査責任)と、それぞれの対策レイヤー。
図1: 全社展開でつまずきやすい3つの不安(学習利用・貼り付け事故・監査責任)と、それぞれの対策レイヤー。
中小企業の管理者から「Claude Codeは便利そうだが、全社で使わせて大丈夫か」という相談が、ここ半年で目に見えて増えました。話を聞くと、技術的な問題ではなく「ルールが無いまま展開して、現場が止まっている」ケースが大半です。本稿はその不安を、社内ルール設計と運用の二段で解く手順を、実際に複数社で運用に乗せた経験を踏まえてまとめます。
Claude Codeを業務で使う上で押さえる3つの情報漏えいリスク
押さえるべきは「学習利用」「貼り付け事故」「監査責任」の3つだけ。残りはこの派生問題です。
Claude Codeの導入相談で出るリスク懸念は無数にあるように見えますが、構造的には3層に集約できます。第1層は「送ったデータがAIの学習に使われないか」という規約レベルの不安。第2層は「従業員が顧客名や個人情報をうっかり貼り付けてしまう」という運用レベルの不安。第3層は「後から監査で問われたとき、誰が何を生成したか説明できるか」という統制レベルの不安です。
第1層は実は規約読解で解決します。Anthropicの商用利用規約(Commercial Terms)には、API・Claude Code経由で送信された入出力は既定でモデル学習に利用しないと明記されています。一方で「不正利用検知や品質向上のため」ログは一定期間保持されます。「学習されない」と「ログが残らない」は別物で、ここを混同したまま現場に説明すると、後で「話が違う」という不信が起きます。一次情報はAnthropicの公式規約ページ(anthropic.com/legal/commercial-terms)で必ず確認してください。
第2層と第3層は規約では守れません。ここから先は社内ルールと運用の領域です。具体的なルール設計を次節以降で示します。
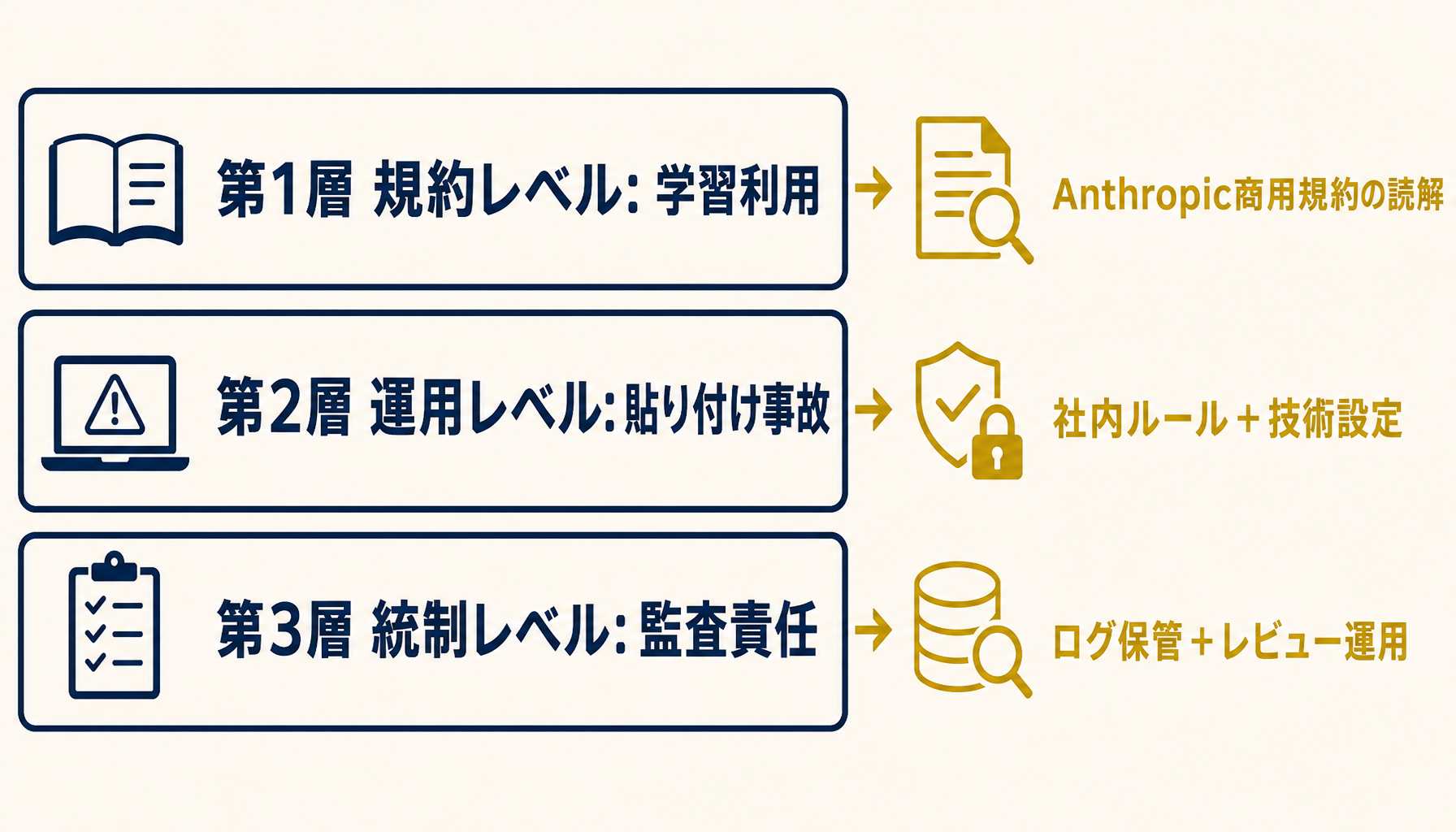 図2: 第1層=規約・第2層=運用・第3層=統制。それぞれ守る場所が違うため、混ぜずに設計する。
図2: 第1層=規約・第2層=運用・第3層=統制。それぞれ守る場所が違うため、混ぜずに設計する。
社内ルールに必ず盛り込む5項目
全社展開前に最低5項目を文書化する。「アカウント」「データ」「成果物」「ログ」「教育」の頭文字で覚えるのが現場に定着しやすい。
社内ルールは網羅性より「最低限を明文化して残りは現場判断」が機能します。実際に複数社で運用に乗せて、必須と判明したのは次の5項目です。
- アカウント発行と停止: 個人アカウントの業務利用を禁止し、会社契約のアカウントを発行する。退職・異動時に48時間以内に停止する責任者を1名指名する。
- データの線引き: 「貼り付けてよいデータ」と「NGデータ」を表で明文化する。NGには顧客個人名・マイナンバー・秘密鍵・未公開の財務数値を最低限含める。
- 生成物のレビュー義務: AIが生成したコードや文書は、本番投入前に人間が1名以上レビューする。レビュー無しの直接コミットを禁止する。
- 監査ログの保管: 誰がいつどのタスクで使ったかを、最低6ヶ月(業界によっては3年)保管する。Claude Codeのセッションログ+Gitの履歴を組み合わせる。
- 初期教育: 新規利用者は30分の動画+ルール確認テストを受けてから業務利用を開始する。
この5項目が言語化されていない状態で展開すると、現場は「触ってよいのか分からない」と止まり、結局Excelに戻ります。逆に5項目さえ固めれば、それ以外は運用しながら追加すれば間に合います。実際に弊社が支援した中小企業3社では、最初の社内ルール文書をA4で2〜3枚に抑え、3ヶ月運用後にFAQを追加する形が定着しました。
ルール文書を作るときに最初から完璧を目指すと、半年経っても展開できません。最低限の5項目を2週間で固めて運用に入る方が、結果として安全なルールが育ちます。自社にどの項目が足りないか棚卸ししたい場合は、初月無料の経営AI診断(通常30万円相当)で現状を可視化し、不足項目だけ集中して埋める進め方が無駄が少なくなります。
 図3: アカウント/データ/成果物/ログ/教育の5項目を1枚に収めた社内ルール文書のレイアウト例。
図3: アカウント/データ/成果物/ログ/教育の5項目を1枚に収めた社内ルール文書のレイアウト例。
データ送信を最小化する設定(OAuth・環境変数・.claudeignore)
「貼り付けない」を人間の注意力に頼らない。Claude Codeの設定で物理的にデータ送信を絞る。
第2層の「貼り付け事故」を技術で減らす方法は3つあります。1つ目はOAuth/APIキーの取り扱い。Claude CodeはOAuthでAnthropicに認証しますが、社内システムへの認証情報(DB接続文字列・APIキー)は環境変数または1Password/macOSキーチェーンに格納し、コード中にハードコードしないルールを徹底します。これは生成AIに限らずセキュリティの基本ですが、Claude Codeを使うとコード提案が「サンプル値で書いて」と促してくることがあるため、改めて全社で確認が必要です。
2つ目は.claudeignoreの活用です。Claude Codeはリポジトリ内のファイルを文脈として読み込みますが、.claudeignoreに指定したパスは送信対象から除外されます。secrets/、.env、顧客名簿CSV、決算データなどを明示的に除外する設定をリポジトリ標準テンプレートに含めると、新規プロジェクトでも忘れません。.gitignoreと.claudeignoreは別管理になる点に注意してください(Git管理外でもClaude Codeは読みます)。
3つ目は「貼り付け前置換snippet」の社内配布です。顧客名を{CUSTOMER_A}に、個人情報を{PERSON_X}に置換するエディタの社内snippetを配布すると、現場が貼り付け前に1秒で匿名化できます。完全な検知は難しいので、運用で「貼る前に1ステップ挟む」習慣を作る方が実効性が高い、というのが現場で得た学びです。
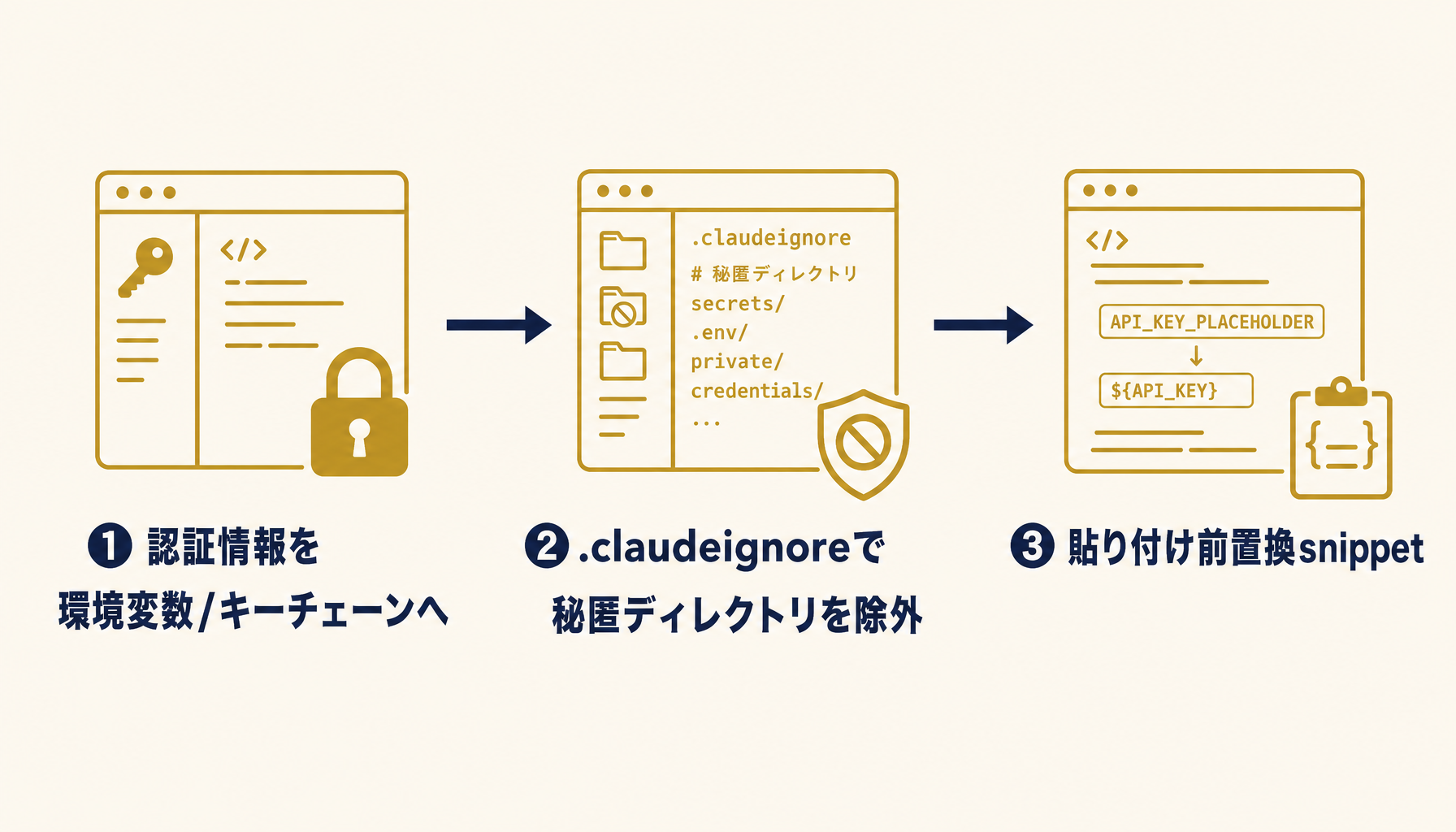 図4: 認証情報の外出し(環境変数・キーチェーン)/ .claudeignoreでの除外/貼り付け前置換snippetの3層構造。
図4: 認証情報の外出し(環境変数・キーチェーン)/ .claudeignoreでの除外/貼り付け前置換snippetの3層構造。
プロンプトに混入させない情報設計
「個人情報・秘密鍵・未公開数値」の3カテゴリを業務文脈に応じて棚卸しする。NGリストは固定でなく業界に応じて拡張する。
プロンプトに混入させてはいけない情報は、業界・業務で大きく変わります。最低ラインは「個人を特定できる情報(個人情報保護法の個人情報)」「認証情報(パスワード・APIキー・秘密鍵)」「未公開の経営数値(決算前の売上・進行中M&A情報)」の3カテゴリです。
中小企業でよく抜けるのが「未公開の経営数値」です。エンジニアが「来月のキャンペーン売上見込みを集計するSQLを書きたい」とClaude Codeに相談する場面は珍しくありません。実際の数値そのものを貼らなくても、未公開のキャンペーン名や独自の指標名を文脈として渡しているケースは多発します。社内ルールに「未公開の経営数値はサンプル値に置換する」を明記し、教育で具体例を見せると現場が腹落ちします。
業界別に追加すべき項目もあります。医療系は患者識別子(個人情報保護法+医療法)、金融系は顧客口座番号・取引履歴、製造業は未公開の設計図面・特許出願前の発明、士業は依頼者の機密事項(弁護士法等の守秘義務)。自社の業界に応じてNGリストを拡張してください。判断に迷う場合は、独立記事の生成AI導入のデータガバナンスと権限設計の落とし穴で業種別の事例を整理しています。
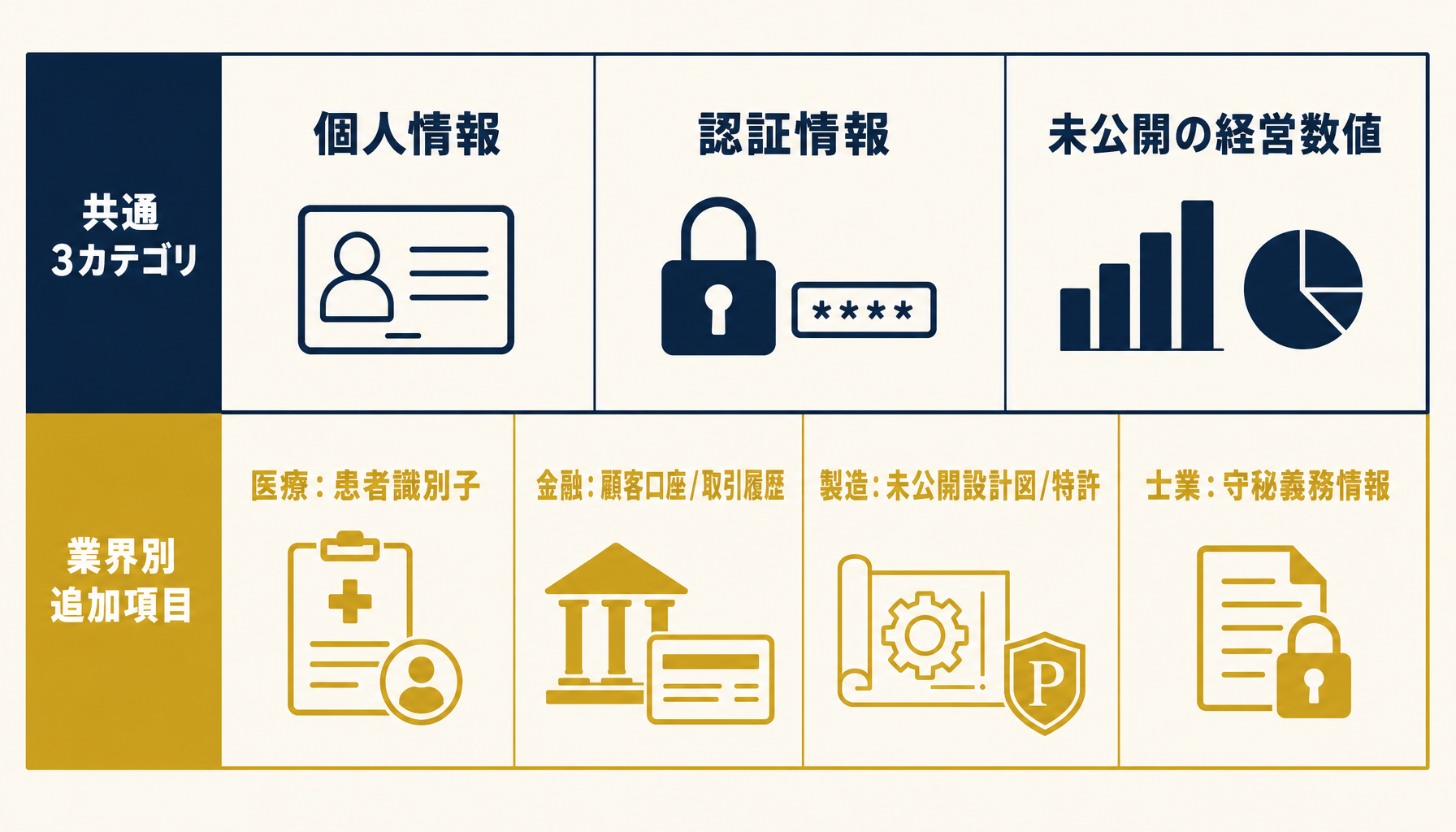 図5: 全業界共通の3カテゴリ(個人情報/認証情報/未公開数値)と、業界別追加項目(医療・金融・製造・士業)。
図5: 全業界共通の3カテゴリ(個人情報/認証情報/未公開数値)と、業界別追加項目(医療・金融・製造・士業)。
監査ログとレビュー運用
「誰が・いつ・何を生成したか」を6ヶ月再現できる状態を保つ。Claude Codeのセッションログ単体では不足、Gitと組み合わせる。
監査要件は業界・規模で温度差がありますが、最低限「6ヶ月遡って誰が何を生成したか説明できる」状態を作ります。Claude Codeのセッションログは~/.claude/配下に保存されますが、これだけでは「どのコードが本番に入ったか」までは追えません。実務では3つのログを組み合わせます。
1つ目はClaude Code側のセッション記録(プロンプトと応答の履歴)。これは利用者個人のPCに残るため、退職時の取り扱いをルール化します。2つ目はGitのコミット履歴。AI生成のコードをコミットする際に、コミットメッセージに[AI-assisted]タグを付ける運用ルールを敷くと、後から検索可能になります。3つ目はPRレビュー履歴。生成物を含むPRには必ず人間レビュアーを1名以上立て、レビューコメントとマージ承認の記録を残します。
監査の観点で重要なのは「AI生成か人間生成かの境界」より「最終責任者は誰か」を明確にすることです。AIが書いたコードでも、コミットして本番に入れた人間が責任を持つ。この線引きを社内ルールに明記すると、現場が「AIのせい」と言わない文化が育ちます。本番化直前のセキュリティ確認は別の観点での監査が必要なため、AIアプリを本番化する前のセキュリティ監査チェックリストも併せて確認してください。
 図6: Claude Codeセッションログ/Gitコミット履歴/PRレビュー履歴を組み合わせて6ヶ月再現可能な統制を作る。
図6: Claude Codeセッションログ/Gitコミット履歴/PRレビュー履歴を組み合わせて6ヶ月再現可能な統制を作る。
全社展開のロードマップ
PoC(1チーム1ヶ月)→ 小規模展開(3〜5チーム3ヶ月)→ 全社展開の3段階で進める。各段階のゲートを文書化する。
社内ルールを固めても、いきなり全社展開すると現場が混乱します。実務で機能している進め方は3段階のロードマップです。
第1段階のPoCは1チーム5名以下・1ヶ月。目的は「自社業務で本当に使えるか」と「ルール案で現場が動けるか」の検証です。この段階でルールの抜け穴が必ず見つかります。例えば「顧客名を{CUSTOMER_A}に置換」というルールが、実際に運用すると「同じ顧客の話を続けると置換が破綻する」など、机上で気づかない問題が出ます。
第2段階は3〜5チーム・3ヶ月の小規模展開。PoCで見つかった抜け穴を反映したルール改訂版で運用します。この段階で監査ログの保管手順、退職時のアカウント停止フロー、新人教育の動画作成を完成させます。コストや使用量の管理についても、この段階で予算枠を決めておくと全社展開で破綻しません(参考: Claude Code利用料を予算内に収める運用Tips)。
第3段階で全社展開。この段階での失敗は「教育コストの過小評価」と「現場のスキル差の放置」です。新規利用者向けの30分動画と、ルール確認テストを必ず必須化してください。テストは点数より「ルールを一度通読させる仕掛け」として機能します。
ロードマップを引いたものの、自社にとってどのチームから始めるべきか・どのルールが優先か判断が難しい場合は、初月無料の経営AI診断(通常30万円相当)で社内の業務マップとリスク棚卸しから一緒に整理する進め方をご案内しています。AIに任せられる業務と人間がレビューすべき業務の線引きまで踏み込んで提案します。
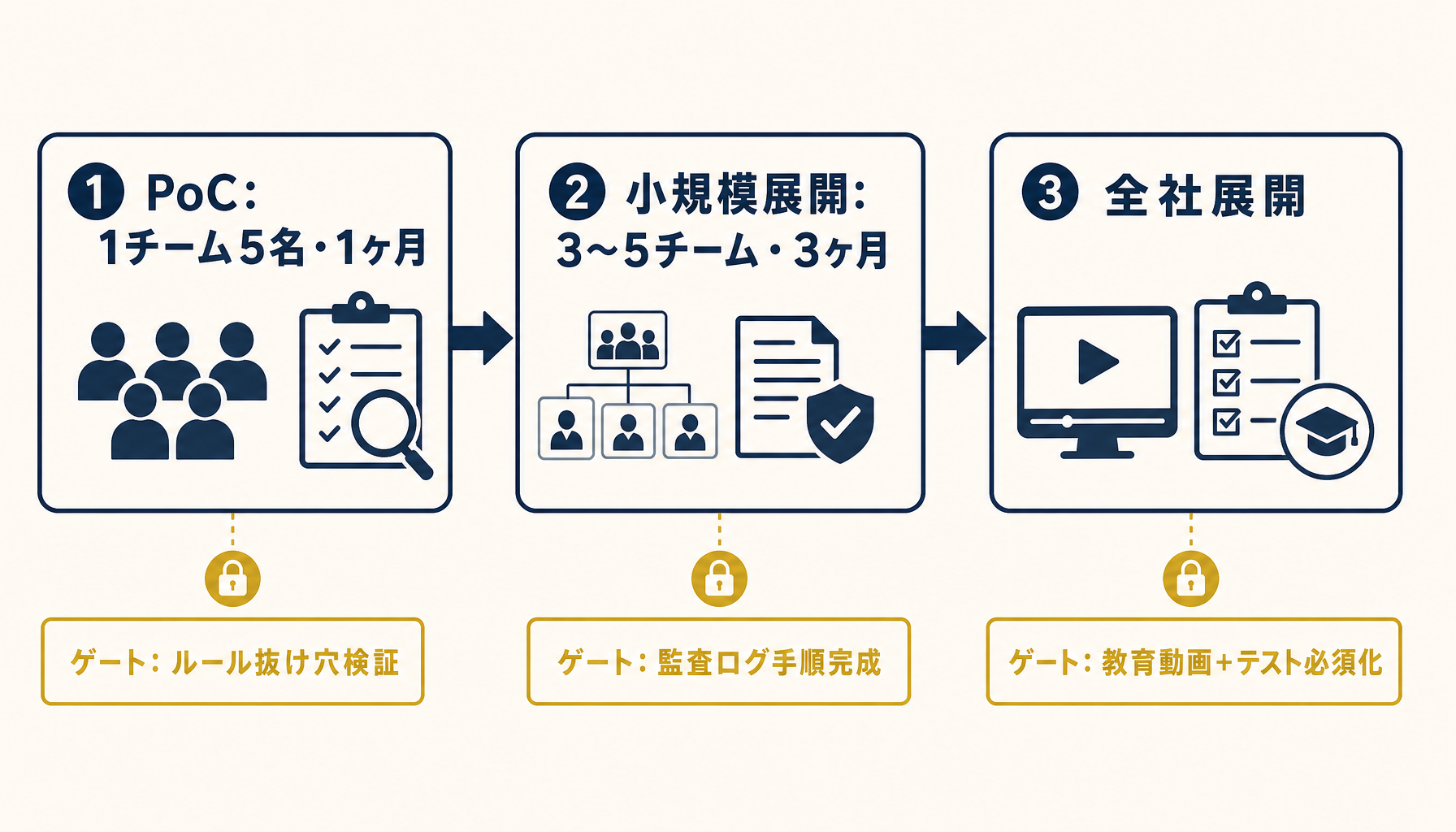 図7: PoC(1チーム1ヶ月)→ 小規模展開(3〜5チーム3ヶ月)→ 全社展開。各段階のゲート項目を明示する。
図7: PoC(1チーム1ヶ月)→ 小規模展開(3〜5チーム3ヶ月)→ 全社展開。各段階のゲート項目を明示する。
まとめと次の一歩
Claude Codeの全社展開でつまずく原因は、技術ではなく「ルール不在」です。本稿で示した5項目の社内ルール(アカウント・データ・成果物・ログ・教育)を2週間で固め、技術設定(環境変数・.claudeignore・置換snippet)と組み合わせて、PoC→小規模→全社の3段階で進めれば、情報漏えいの不安は構造的に抑え込めます。
自社で社内ルール案を作り始めたものの「どこまで書けば十分か」「自社の業界にどの追加項目が必要か」で迷ったら、初月無料の経営AI診断(通常30万円相当)をご活用ください。貴社の業務マップと現行の情報管理体制を一緒に棚卸しし、Claude Code導入で具体的にどこを改善すれば良いかの提案までお持ちします。面談形式で進めるため、社内ルール文書のドラフトレビューもその場で対応可能です。
よくある質問
Claude Codeに渡したコードや会話はAIの学習に使われますか
Anthropicの商用利用規約(Commercial Terms)では、API・Claude Code経由で送信した入出力をモデル学習に既定では利用しないと明記されています。ただし「信頼性とリスク低減のため」運用ログは一定期間保持されます。社内ルールでは「学習対象外であること」と「ログは保持される」ことの両方を従業員に伝える設計が安全です。最新の規約は必ずAnthropic公式(anthropic.com/legal/commercial-terms)で確認してください。
Claude Codeを全社展開する前に最低限決めるべきルールは何ですか
実務で詰まりやすいのは5項目です。1)アカウント発行と退職時の停止フロー、2)貼り付けてよいデータ/NGデータの線引き、3)生成物のレビュー義務、4)監査ログの保管期間、5)新人向けの初期教育。この5つが言語化されていないまま展開すると、現場が「触ってよいのか分からない」状態で止まります。本稿の§2で具体テンプレを示します。
顧客名や個人情報をうっかり貼り付けないようにする仕組みはありますか
完全自動の検知は難しいので、運用と技術の二段で組みます。運用は「貼り付け前に置換する用語表」を作り、技術は.claudeignoreで秘匿ディレクトリを除外し、env系の機密はOSのキーチェーンや環境変数経由で扱います。社内チャットでよくある「お客様名そのまま貼り付け」を、置換コマンドの社内snippet化で物理的に減らすのが一番効きます。
監査の観点で残しておくべきログは何ですか
最低限「誰が」「いつ」「どのリポジトリで」「どの種類のタスクを」「何件」実行したかの4要素を残します。Claude Code自体のセッションログ(~/.claude/)に加え、Gitのコミット履歴とPRレビュー履歴をセットで保管すると、後から「このコードはAI生成か人間生成か」「責任者は誰か」を再構成できます。監査要件のある業界では、生成物を含むPRに必ず人間レビュアーを1名以上立てるルールを併用します。
関連記事
- Claude Codeで業務自動化 中小企業の導入ステップとROI試算 — 関連: Claude Codeの導入効果の試算
- Claude Code導入で何が変わるか 受託開発の現場でのリアルな使い方 — 関連: 実務での使い方の一次情報
- Claude Code利用料を予算内に収める運用Tipsプラン選択と使い分け — 関連: 全社展開時のコスト管理
- 生成AI導入のデータガバナンスと権限設計の落とし穴 — 関連: 業種別の権限設計
- AIアプリを本番化する前のセキュリティ監査チェックリスト — 関連: 本番化直前のセキュリティ確認(別cluster)
「まず費用感だけ知りたい」という方へ。
1分で概算費用がわかるシミュレーターをご用意しています。
よくある質問
- Q. Claude Codeに渡したコードや会話はAIの学習に使われますか
- A. Anthropicの商用利用規約(Commercial Terms)では、API・Claude Code経由で送信した入出力をモデル学習に既定では利用しないと明記されています。ただし「信頼性とリスク低減のため」運用ログは一定期間保持されます。社内ルールでは「学習対象外であること」と「ログは保持される」ことの両方を従業員に伝える設計が安全です。最新の規約は必ずAnthropic公式(anthropic.com/legal/commercial-terms)で確認してください。
- Q. Claude Codeを全社展開する前に最低限決めるべきルールは何ですか
- A. 実務で詰まりやすいのは5項目です。1)アカウント発行と退職時の停止フロー、2)貼り付けてよいデータ/NGデータの線引き、3)生成物のレビュー義務、4)監査ログの保管期間、5)新人向けの初期教育。この5つが言語化されていないまま展開すると、現場が「触ってよいのか分からない」状態で止まります。本稿の§2で具体テンプレを示します。
- Q. 顧客名や個人情報をうっかり貼り付けないようにする仕組みはありますか
- A. 完全自動の検知は難しいので、運用と技術の二段で組みます。運用は「貼り付け前に置換する用語表」を作り、技術は.claudeignoreで秘匿ディレクトリを除外し、env系の機密はOSのキーチェーンや環境変数経由で扱います。社内チャットでよくある「お客様名そのまま貼り付け」を、置換コマンドの社内snippet化で物理的に減らすのが一番効きます。
- Q. 監査の観点で残しておくべきログは何ですか
- A. 最低限「誰が」「いつ」「どのリポジトリで」「どの種類のタスクを」「何件」実行したかの4要素を残します。Claude Code自体のセッションログ(~/.claude/)に加え、Gitのコミット履歴とPRレビュー履歴をセットで保管すると、後から「このコードはAI生成か人間生成か」「責任者は誰か」を再構成できます。監査要件のある業界では、生成物を含むPRに必ず人間レビュアーを1名以上立てるルールを併用します。
あわせて読みたい