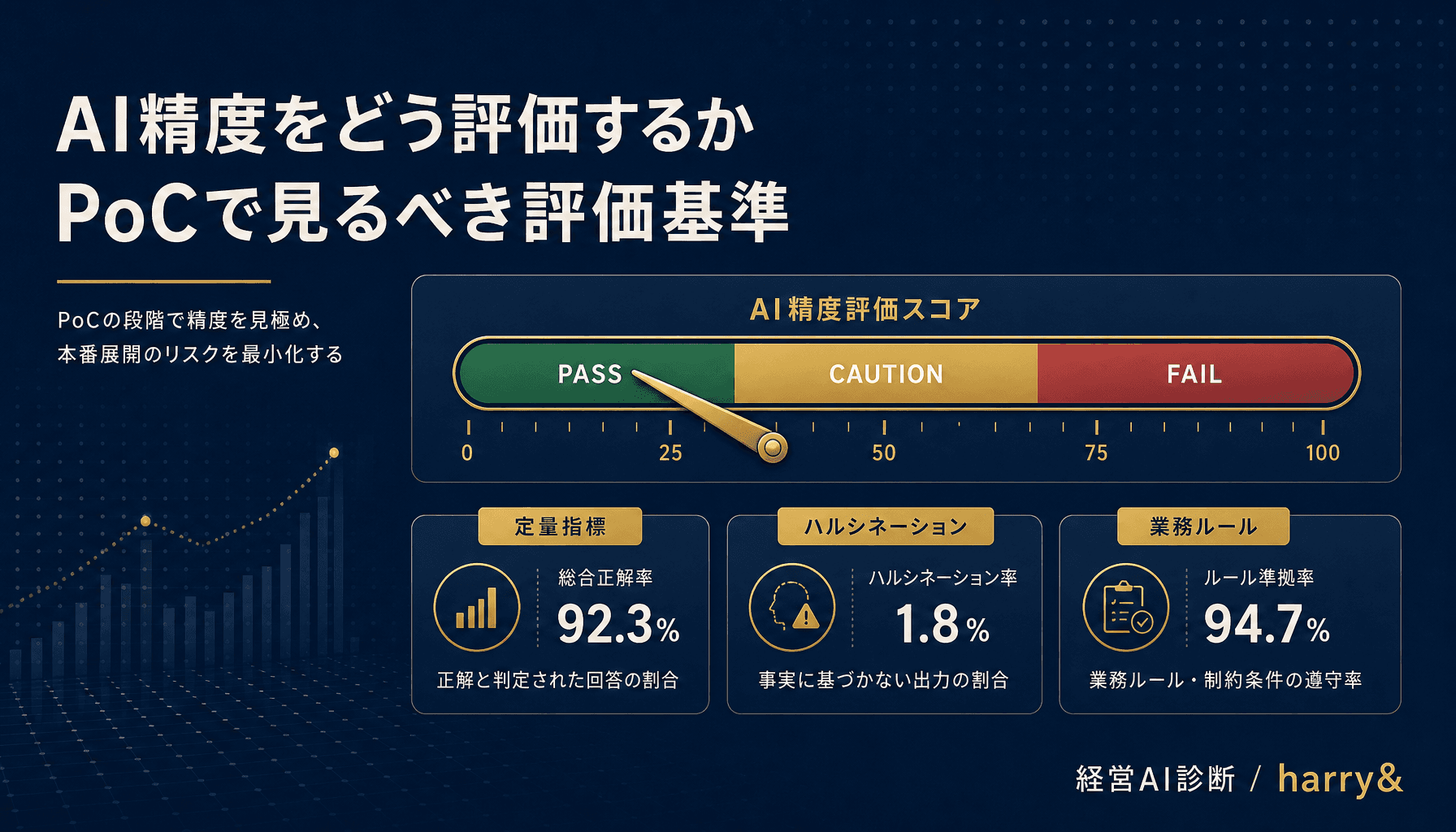
AIの「精度」は正解率だけでは測れない。PoCで見るべき評価基準を、指標・データセット・合格ラインの3点で本番判定できる実務レベルに落とし込む。
 無料相談受付中
無料相談受付中いきなり作らない。
AIで何がどう変わるかを、先に見極める。
- ノーコードの卒業先、AIネイティブ受託。事業の文脈で要件から実装まで伴走
- 45分・Web。検討段階のご相談・資料だけでも歓迎。しつこい追客はしません
目次
AIの精度をどう評価するか PoCで見るべき評価基準と本番判定の実務
AIの「精度」は正解率だけでは測れない。PoCで見るべき評価基準を、指標・データセット・合格ラインの3点で本番判定できる実務レベルに落とし込む。
AI精度評価が「正解率」だけでは足りない理由
AIの精度評価を正解率一本で判断すると、本番でほぼ確実に事故る。
実際の相談現場で多いのは、PoCで「正解率85%出ました」というレポートを受け取り、経営者が本番GOを出したあと、1ヶ月で「思ってた品質と違う」と揉めるケースだ。正解率85%というのは、100件中85件が「何らかの意味で正解」だっただけで、業務が回るかどうかとは別の話になる。
精度を正しく測るには、少なくとも4つの軸を分けて考える必要がある。1つめは正確性(Accuracy)で、出力が正解と一致しているか。2つめは完全性(Completeness)で、必要な情報が抜けていないか。3つめは一貫性(Consistency)で、同じ入力に対して同じ出力が返るか。4つめは業務適合性(Business Fit)で、フォーマット・禁則・文字数などの業務ルールを守れているか。
正解率85%でも、完全性が60%(必要な項目が4割抜けている)なら業務は回らない。逆に正解率70%でも、抜けがなく修正しやすい形で出るなら業務担当者は捌ける。数字だけを追いかけると、本番で使える品質かどうかの判断を誤る。
もう1つ落とし穴になるのが、評価データの偏り。PoC用に選ばれた10件が「うまく動きそうな典型例」ばかりだと、本番でエッジケースに触れた瞬間に精度が崩れる。これも「PoCで動いたのに本番で落ちる」典型パターンだ。本番判定にはデータの代表性の担保が欠かせない。
PoCで見るべき評価指標 3種類の使い分け
PoCで実装すべき評価指標は、業務の性質に応じて3種類を組み合わせる。単一指標で判断しないのがポイントだ。
1つめは定量指標(Quantitative Metric)。テキスト生成なら埋め込みベクトルのコサイン類似度、構造化抽出ならフィールド一致率、分類タスクならF1スコアを使う。「機械的に自動計算できる」ことが最大の利点で、評価バッチをGitHub ActionsなどのCIに組み込めば、毎日勝手に回る。
2つめはハルシネーション検知(Hallucination Check)。LLMが「もっともらしい嘘」を出していないかを判定する。出力に含まれる固有名詞・数値・日付が、入力や参照ナレッジベースに実在するかを機械的に照合する仕組みだ。近年はLLM-as-a-Judge手法(別のLLMに「この出力は事実か」と判定させる)も使われるが、判定側LLMのバイアスに注意する。
3つめは業務ルール違反検知(Rule Violation Check)。出力フォーマット、禁則語、文字数、必須項目の欠落など、業務要件として決めた制約を満たしているかをコードでチェックする。正規表現・JSONスキーマ・辞書照合で実装できる領域で、コストゼロで導入できる。
この3種類は「機械が拾える範囲」と「人でしか拾えない範囲」の境界を明確にする役割も果たす。3種類で拾えないもの(自然さ・ブランドトーン・微妙なニュアンス)だけを人がスポットチェックすれば、評価工数は月次3〜5時間に収まる。詳しくはPoCで動いたAIを落ちない本番にする運用設計 評価と監視の実装手順で運用設計の全体像を扱っている。
自社のどの業務にどの評価指標を組み込めばいいか迷ったら、初月無料の経営AI診断(通常30万円相当)で業務ごとに切り分ける整理から一緒に始めることもできる。
評価データセットの作り方 50件から100件で足りる
評価データセットは50件から100件で十分に回る。1000件を目指すと準備で数週間止まるので、まず50件を集めるところから始める。
内訳の目安は「典型例30件・過去に間違えた10件・エッジケース10件」の50件構成だ。典型例は本番で最も高頻度に発生するパターンで、日常的な精度を測る土台になる。過去に間違えた10件は、業務担当者に「AIが困りそうなケース」を出してもらう。エッジケースは、極端に短い/長い、業界特殊表記、他言語混入など、想定外を狙って集める。
各データには入力と「正解」をペアで用意するが、「正解を1つに限定しない」ことが重要だ。LLMは同じ意味の内容を違う言い回しで出すので、正解を1つに絞ると類似度スコアが不当に下がる。代わりに「合格例のバリエーション」を2〜3個用意し、いずれかに類似度0.8以上なら合格、といった判定にする。
評価データセットは業務担当者と一緒に作る。開発担当者だけで作ると「機械が測りやすいデータ」に偏り、業務で本当に困るケースが漏れる。業務担当者が過去1ヶ月に処理した実データから代表例を選ぶ形が現実的に回る。
作成後は評価データセットもバージョン管理する。GitでYAML/JSONで管理し、業務仕様が変わったら新バージョンで運用する。旧バージョンとの差分を追えるようにしておくと、精度が変動したときに「モデルが変わったのか」「業務仕様が変わったのか」を切り分けられる。
合格ラインの決め方 「間違えたときのコスト」から逆算
「精度何パーセントで本番に出すか」に絶対解はない。合格ラインは「間違えたときの復旧コスト」から逆算して決める。
判断軸は3段階に分けられる。1段階目は「人が二次チェックする業務」で、AIが下書きを作り人が最終確認する形。合格ラインは60〜70%程度でも回る。人の負荷が減れば十分成功で、AIが間違えても人がリカバリーできる。議事録の一次案作成、社内メールの下書き、資料の骨子生成などがこの領域だ。
2段階目は「業務担当者が例外だけ介入する業務」で、9割はAIが自動処理し1割を人が処理する形。合格ラインは85〜90%が目安になる。問い合わせの一次分類、書類の項目抽出、定型メール返信などが該当する。エラーが業務担当者に集約されるので、担当者の負荷が読める設計が必要だ。
3段階目は「顧客に直接返す業務」で、AI出力がそのまま顧客に届く形。合格ラインは95%以上と、誤答時のフォロー動線(エスカレーション、訂正謝罪、返金)が必須になる。カスタマーサポートの自動応答、法的文書の生成、金融判断への関与などはこの領域で、慎重な設計判断が要る。
重要なのは「PoC開始前に合格ラインを合意しておく」ことだ。事前に決めないと、PoC後に「もう少しなんとかならないか」と押し戻しが発生し、判断が延々と伸びる。数字とその根拠(間違えたときの復旧コスト)を先に合意し、PoCはそのラインを超えるかどうかだけを見る設計にする。
PoC結果を本番判定に落とし込む3ステップ
評価指標とデータセットと合格ラインが揃ったら、PoC結果を本番判定に落とし込む3ステップに進む。
ステップ1は「合格ラインとのギャップを可視化する」。3種類の指標それぞれについて、実測値と合格ラインとの差分を数字で出す。定量指標82%(合格ライン85%)、ハルシネーション率5%(合格ライン3%)、ルール違反12件(合格ライン0件)といった形で、どこがどれだけ足りないかを明確にする。GOかNGかの一言判定ではなく、ギャップベースで議論する。
ステップ2は「ギャップの原因を切り分ける」。プロンプトの改善で埋まるものか、モデル変更で埋まるものか、業務側でルール変更が必要なものか、原因ごとに分類する。プロンプト改善は1〜2週間、モデル変更(GPT-4→Claude 3.5等)は1週間、業務ルール変更は関係部署との調整で数週間かかる。原因を切り分けないと「もう少しやってみます」で漂流する。
ステップ3は「NGなら止める・部分導入・再PoCの3択で決断する」。全指標クリアなら本番へ、いずれか未達なら (a) 完全に止めて別業務に切り替え (b) 対応できる範囲に絞って部分導入 (c) 課題を潰して再PoC、の3択を経営判断として決める。「もう少し改善して」を繰り返すと、PoCが半年以上塩漬けになる。3ヶ月時点で決断する運用が現実的だ。
このステップを回すと、PoC結果の解釈で揉めなくなる。数字が独り歩きせず、事前合意したラインと突き合わせるだけの単純作業になるからだ。詳しい費用感は中小企業のAI導入 費用相場と内訳も参考になる。
中小企業がやりがちな評価の失敗パターン
最後に、中小企業のAI導入相談で頻繁に見る失敗パターンを3つ挙げる。
1つめは「デモ動画で判断する」パターン。ベンダーが持ち込んだデモは、うまく動くケースを厳選している。それを見て「すごい、うちでも使える」と本番判定してしまうと、本番データで動かない。デモは「機能があること」を見るためのものであり、「精度」を判定するものではない。判定は必ず自社の実データで行う。
2つめは「1ヶ月PoCで精度が良ければ本番」パターン。1ヶ月では季節性や業務サイクルの変動を捉えられない。月末月初で入力が変わる業務、季節で内容が変わる業務は、少なくとも2〜3ヶ月のPoCで精度の変動を見る必要がある。「1ヶ月良かった」を根拠に本番化すると、翌月に精度が崩れる。
3つめは「評価データセットを更新しない」パターン。本番運用開始後も、評価データセットはPoC時のまま。半年経つと業務仕様や入力パターンが変わり、評価スコアと本番実感がズレる。四半期ごとに実データから20件程度を追加し、古いエッジケースは削除する運用が必要だ。ベンダー選定の段階で運用設計まで含めた提案があるかは重要な差別化ポイントで、AIベンダーの選び方 中小企業が失敗しない判断基準も参考になる。
まとめ 本番判定は「事前合意した数字」で決める
AI精度評価の本番判定は、3つの決めごとで揺るがなくなる。
1つは「4軸で見る」こと。正解率だけでなく、完全性・一貫性・業務適合性を分けて評価する。2つは「50件データセットで機械評価を回す」こと。1000件は不要で、業務担当者と一緒に選んだ50件で十分に本番判定できる。3つは「合格ラインを事前に決めておく」こと。業務の復旧コストから逆算した数字を、PoC開始前に経営と現場で合意する。
この3点が揃うと、PoC後の判断が「事前合意ラインと実測を突き合わせるだけ」の作業になる。数字の解釈で揉めず、GO/NGが3ヶ月以内に出る。逆に3点が揃っていないと、PoCが半年・1年と塩漬けになり、投資判断が遅れる。
自社のどの業務からAI精度評価を組めばいいか、合格ラインをどう設計するか迷ったら、初月無料の経営AI診断(通常30万円相当)で現状の業務と評価可能なポイントを一緒に可視化する形で始められる。診断のあと本番化の設計まで一緒に走らせるかは、その時点で判断してもらえばよい。
関連記事
- PoCで動いたAIを落ちない本番にする運用設計 評価と監視の実装手順 — 関連: 評価と監視の運用設計
- 中小企業のAI導入 費用相場と内訳 — 関連: PoC・本番の費用感
- AIベンダーの選び方 中小企業が失敗しない判断基準 — 関連: ベンダー選定基準
- AIエージェント導入でよくある失敗 中小企業の予防策 — 関連: 導入時の落とし穴
- 中小企業がClaude Codeで業務自動化する導入ステップとROI試算 — 関連: 具体的な自動化事例
「まず費用感だけ知りたい」という方へ。
1分で概算費用がわかるシミュレーターをご用意しています。
よくある質問
- Q. PoCの精度評価に何件のデータを用意すればいいか
- A. 本番の入力を代表する50件から100件が目安になる。10件では偶然でスコアがブレるし、1000件も揃えると準備だけで数週間かかり判断が遅れる。50件を「典型例30件・過去に間違えた10件・エッジケース10件」で組めば、業務判定に十分な粒度が出る。データが揃わない業務は、そもそも本番化してもチェックできないので、まず50件集める作業自体をPoCに含めるのが現実的だ。
- Q. 精度何パーセントあれば本番に出していいのか
- A. 業務によって合格ラインは変わるので「一律の数字」は存在しない。判断軸は「間違えたときの復旧コスト」で決める。人が二次チェックする業務なら70%前後でも回るし、顧客に直接返す業務なら90%以上と誤答時のフォロー動線が必須になる。数字より重要なのは、事前に「このスコアを下回ったら本番に出さない」という止めるラインを合意しておくことだ。
- Q. LLMは同じ入力でも出力がブレる 評価は成立するのか
- A. 成立させる方法はある。1つは同じ入力を複数回試行して平均・分散を出す。2つめは埋め込みベクトルの類似度で「意味が同じか」を判定する。3つめは正解を1つに絞らず「合格例のバリエーション」で複数許容する。ブレを許容する評価設計にできれば、LLMの本番判定は十分回る。厳密一致で評価しようとするから成立しなくなる。
- Q. 評価スコアは誰がどれくらいの頻度で見るべきか
- A. PoC中は開発担当者が週次で見て、本番後は業務担当者が月次で見る形が現実的に回る。人を増やす必要はなく、Slackに評価バッチの結果を自動通知して、閾値割れだけをレビュー対象にすればよい。毎回全件見ようとすると続かない。「アラートが出たときだけ人が動く」設計にすれば、月30分の工数で品質は維持できる。
あわせて読みたい